
في إحدى ليالي نوفمبر 2016، أظهر موقع «غوغل للترجمة» (Google Translate) تحسنًا مفاجئًا في عدد من اللغات أدهش مستخدميه.
الشبكات العصبية الاصطناعية هي التقنية التي يستخدمها «فيسبوك» للتعرف على وجوه أصدقائك في الصور التي ترفعها.
يشتهر الموقع عادة بترجمته الحرفية الفجة، التي تجعله موضوعًا للسخرية أحيانًا. يمكنك إجراء تجربة صغيرة بنفسك؛ استخدمه لترجمة (Gents Restroom)، ومعناها «حمام الرجال»، من الإنجليزية للعربية، لترى أنه يترجمها (حتى لحظة كتابة هذا الموضوع) إلى «أيها السادة مرحاض».
لكن الحال يختلف عند الترجمة لليابانية مثلًا من بين لغات أخرى (الإنجليزية والإسبانية والبرتغالية والفرنسية والألمانية والتركية والصينية والكورية، كبداية). فعندما استُخدم الموقع أوائل العام الماضي لترجمة مقاطع من رواية «غاتسبي العظيم» (The Great Gatsby) من الإنجليزية لليابانية، وقورنت ترجمته بالنسخة التي ترجمها «هاروكي موراكامي» (Haruki Murakami)، اتضح أن «غوغل» أضحى منافسًا شرسًا للأديب العالمي فيما يبدو.
ويستشكف أحد مقالات جريدة «نيويورك تايمز» هذه الطفرة في أداء الموقع، ويسرد قصة فريق العمل المسؤول عنها.
اقرأ أيضًا: انحيازات ويكيبيديا: هل الموسوعة «حرة»؟
عقل «غوغل»
كانت «غوغل» قد أعلنت في سبتمبر 2016 سعيها لدمج تقنيات الذكاء الاصطناعي مع موقعها للترجمة.
ويعمل أحد قطاعات المؤسسة، المسمى «عقل غوغل» (Google Brain)، على بحث وتطوير تقنيات الذكاء الاصطناعي والاستفادة منها، منذ تأسيسه عام 2011 للبحث النظري والتطبيقي في الشبكات العصبية الاصطناعية (Neural Networks) أو التعلم العميق (Deep Learning).
ويمكن إعطاء فكرة مبدئية عن الشبكات العصبية الاصطناعية بالإشارة إلى أنها التقنية التي يستخدمها «فيسبوك» مثلًا للتعرف على وجوه أصدقائك في الصور التي ترفعها على الموقع.
العقول التي تقف وراء «عقل غوغل»

يحكي مقال «نيويورك تايمز» عن المصادفة التي جمعت «جيف دين» (Jeff Dean) بـ«آندرو نِغ» (Andrew Ng). كان الأول موظفًا قديمًا في «غوغل»، قرر بعد مقابلة «نغ»، الذي كان باحثًا متحمسًا للشبكات العصبية الاصطناعية، أن يخصص جزءًا من وقته لبحث التقنية وتطبيقاتها المحتملة. أصبح «دين» بالتالي رئيسًا فعليًّا لـ«عقل غوغل»، التي وُلدت من هذه المقابلة بين الرجلين.
بعد فترة، سيصبح لجهود «جيفري هينتون» (Geoffrey Hinton) دور كبير في توجيه البحث. «هينتون» كان منجذبًا للشبكات العصبية الاصطناعية منذ سنوات دراسته الجامعية في الستينات، في وقتٍ كانت الفكرة تُقابل فيه إما بالرفض أو عدم الفهم، كما كان قد فاز للتو مع فريق من الباحثين بمسابقة لتصميم برنامج للتعرف على الصور، عندما قررت «غوغل» الاستعانة به.
كانت جهود الثلاثة وبحوثهم وراء الطفرة الهائلة التي حققتها منصة الترجمة، بالإضافة إلى عمل «مايك شوستر» (Mike Schuster)، الذي سارع إلى محاولة دمج التقنية في الموقع.
لكن ما هي الشبكات العصبية الاصطناعية بالضبط؟ وكيف استطاعت نقل «غوغل للترجمة» من كونه ذلك المترجم الساذج الذي نعرفه، إلى آخر أكثر رهافة يمكن مقارنته بالمترجمين من البشر؟
الجديد في الشبكات العصبية الاصطناعية
منذ صُكَّ مصطلح «الذكاء الاصطناعي» في خمسينات القرن العشرين، يسيطر على ذلك المبحث منهج معروف باسم «الذكاء الاصطناعي الرمزي» (Symbolic AI). اعتقد أتباع ذلك المنهج أن الطريق إليه يكون بكتابة برامج ضخمة وحشوها بقواعد التفكير المنطقي وبكَمٍّ معقول من المعرفة في العالم، وهو ما سيسمح للآلة أن تسلك سلوكًا ذكيًّا، بعد تطبيق «القواعد» المعطاة سلفًا باستخدام «المعرفة» المعطاة سلفًا كذلك للتعامل مع المواقف المستجدة.
لو افترضنا أنك توَدُّ تصميم برنامج للتعرف على صور القطط مثلًا كالذي صممه «هينتون»، فإنك ستبدأ بإمداد برنامجك بمعلومات عن القطط: لها أربع أرجُل وأذنان حادتان وشارب وذيل... إلخ.
يُخزِّن البرنامج هذه المعلومات في ذاكرة الحاسب، ويستخدمها للتعرف على صور القطط عن طريق قاعدة جامدة؛ فبعد التعرف على مختلف عناصر الصورة، لو عثر البرنامج على جسم له أربع أرجُل وأذنان حادتان وشارب وذيل، يعرف أنه قطة.
يلجأ هذا المنهج إلى بناء الذكاء الاصطناعي من الأعلى، بإمداد البرنامج بالقواعد العامة (صفات القطط) التي ينبغي تطبيقها بعد ذلك على البيانات الجزئية (صور القطط). لكن في مقابل هذا التصور، قامت رؤية معارضة كانت ذات شعبية ضئيلة في البداية، إذ دعت أقلية من الباحثين إلى بناء الذكاء الاصطناعي من الأسفل؛ عن طريق تغذية البرنامج بالبيانات وتركه يعمل على تجريدها للوصول إلى قواعد عامة.
أمخاخ افتراضية
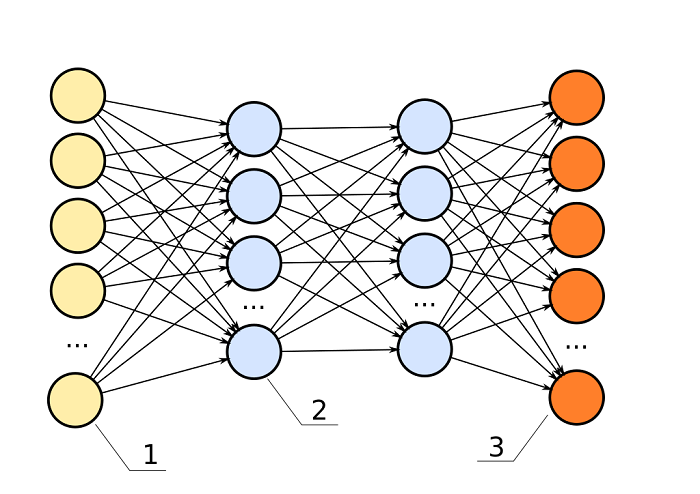
مخطط لشبكة عصبية اصطناعية من ثلاثة مستويات
اعتمدت هذه الفكرة على المخ البشري نموذجًا لعمل الذكاء الاصطناعي. ويتكون المخ من نحو 100 مليار خلية عصبية، يتصل كل منها بقرابة 10,000 خلية أخرى عن طريق وصلات عصبية.
والفارق طبعًا أن برامج الذكاء الاصطناعي تقوم على شبكات أصغر كثيرًا، وهي بالإضافة لذلك شبكات «افتراضية» غير عضوية، أي إنها مجرد برنامج كمبيوتر مصمم ليحاكي طريقة عمل الخلايا العصبية والوصلات بينها.
وتعمل الشبكة العصبية الاصطناعية كالتالي: تؤدي المعطيات المختلفة إلى إثارة الشبكة بطرق مختلفة، وبالتالي تنتهي بها إلى مُخرجات مختلفة. وتربط الشبكة، عن طريق التغذية الإرجاعية (Feedback)، على ربط معطيات معينة بمُخرجات معينة.
لنفكر مجددًا في صور القطط. تثير هذه الصور عند تقديمها للشبكة مجموعة بعينها من خلايا عصبية في مستوى أول، تمرر الإثارة بدورها إلى خلايا أخرى في مستوى أعمق، وهكذا، حتى تنتهي الإشارة إلى مستوى «المُخرَجات»، أو المستوى الأخير في الشبكة. ولأن كل صور القطط تشترك في سمات معينة (هي بالضبط سمات القطط)، فإنها تؤدي إلى أنماط معينة من الإثارة، وبالتالي إلى إنتاج مُخرَجات بعينها.
إذًا، يُغرق مطور البرنامج الشبكة بمعطيات من صور بعضها لقطط وبعضها دون قطط، ويعرِّف البرنامج إذا ما كانت الصورة تحتوي «قطة» أم لا، وهكذا يَسِم البرنامج مُخرجاته تباعًا، إما «قطة» أو «ليست قطة». وبعد تقديم عدد كافٍ من المعطيات، يستطيع البرنامج التوصل وحده بشكل صحيح إلى ما إذا كانت الصورة تحتوي على قطة أم لا، لأنها تؤدي إلى أنماط الإثارة الموسومة «قطة» نفسها.
الفارق الأهم بين هذه التقنية والتقنية الرمزية التقليدية هو أنه لا المبرمِج ولا البرنامج يعرفان ما يجعل القطة «قطة»؛ أي ما هي بالتحديد القواعد التي يتم وفقًا لها التعرف على صورة القطة وتمييزها عن أي صورة أخرى. هذه القواعد غير منصوص عليها في كود البرنامج، لكنها مُضمرة بدلًا من ذلك في نمط التنشيط أو الإثارة الذي يصل المُدخَل (صورة القطة) بالمُخرَج (الوسم «قطة»).
لكن كيف تعمل هذه التقنية في سياق «غوغل للترجمة»؟
بعيدًا عن القطط

بعد أن صمم فريق «غوغل» شبكة عصبية اصطناعية ليعمل موقع الترجمة عبرها، لجأوا إلى تغذية البرنامج بكميات هائلة من النصوص المترجمة سلفًا، اشتملت مثلًا على جميع سجلات البرلمان الكندي؛ وهي ملايين الصفحات المكتوبة بلغتين. يستطيع الموقع أن يصل المُدخَلات (وهي الجمل باللغة الأولى) بالمُخرَجات (الجمل باللغة الثانية)، ليكون قد خطا بالفعل أول خطوة لتعلم الترجمة بين اللغتين دون أن يُبرمج بقاعدة نحوية واحدة.
علاوة على ذلك، يُعدُّ التطور المستمر من أهم ميزات الشبكة العصبية الاصطناعية. لن يتوقف «غوغل للترجمة» عند المستوى الذي وصل إليه حاليًا؛ بل سيستمر في التطور وتحقيق درجات أعلى من كفاءة الترجمة، طالما ظل يتلقى تغذية إرجاعية على عمله. هذا هو السبب الذي من أجله يطلب «فيسبوك» رأيك طول الوقت في نظامه للإعلانات.
لكن إلامَ تنتهي هذه العملية؟ هل يحل «غوغل للترجمة» محل المترجم البشري يومًا ما؟
قد يعجبك أيضًا: خبير سابق في «غوغل» يرصد كواليس هوسنا بوسائل التواصل الاجتماعي
الذكاء الاصطناعي والإبداع البشري

يتطور الذكاء الاصطناعي بسرعة شديدة، وتزداد مع هذا التطور ثقتنا العامة في إمكاناته، وفي الاحتمالات التي قد يأتي بها بعد ذلك. لكن الفكرة تقابَل عادة بدرجة من عدم الارتياح؛ بسبب طعنها في فرادة الكائن البشري من جهة، وصعوبة استيعاب الكيفية التي يمكن أن تنشأ بها أنشطة خلاقة عن برامج الكمبيوتر الآلية من جهة أخرى.
ورغم أن الذكاء الاصطناعي له الآن بالفعل تجارب في الفن التشكيلي والموسيقى والأدب، وحتى محاولات لإلقاء النكات، فإنه تظل ثمة صعوبة في التوفيق بين العمل الآلي لبرنامج الحاسب والنشاط العقلي المعقد للإنسان.
إن الجملة الافتتاحية لرواية «الغريب» تُرجمت من الفرنسية إلى الإنجليزية عام 1946، لكن ظل الجدل دائرًا بخصوص الترجمة الأدق حتى 2012، أي طَوَال 66 عامًا، وربما لا يتوقف هذا الجدل أبدًا.
فهل نستطيع مع ذلك أن نؤمن بقدرة «غوغل للترجمة» أن يحلَّ محل المترجم البشري؟ وما الذي يمكن أن يضيفه الذكاء الاصطناعي إلى فهمنا لطبيعة الترجمة وإشكالياتها؟



